
自然语言处理课上做了一个有趣的大作业,于是把它记录下来。
模型代码和数据集文件已经上传至github:https://github.com/MSilke/bert_classifier
一 题目介绍
设计一个关于文本分类的课程大作业,旨在让学生掌握文本分类的基本概念、数据预处理、模型训练、评估和部署等关键步骤。学生将通过实际操作,理解文本分类在自然语言处理中的应用,并能够使用不同的算法和技术来解决实际问题。
二 数据集选择
在数据集的选择上,我选择了MR数据集作为我们大作业的任务。MR数据集是一个有关电影评论的数据集,包含积极评论和消极评论两种类别的标签。
三 数据预处理
实验给定的MR数据集只包含两个.txt文件,如下所示:

其中,mr.txt文件中包含了超过1万条的用户评论,而mr_labels.txt则对用户评论给定了标签,划分了训练集和测试集。
在对数据预处理的过程中,我们使用了pandas库,pandas是基于Numpy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
为了更方便地提取数据集中的信息,我们选择将mr_labels文件转换为csv格式,将对应的id、标签等信息截取到表中,利用python代码实现如下:
import csv
# 读取txt文件
txt_file_path = 'mr_dataset/mr_labels.txt'
csv_file_path = 'mr_dataset/mr_labels.csv'
csvFile = open(csv_file_path, 'w', newline='', encoding='utf-8')
writer = csv.writer(csvFile)
csvRow = []
# 打开txt文件
f = open(txt_file_path, 'r', encoding='utf-8')
# 逐行读取txt文件中的内容,并依据间距空格进行csv格式的划分
for line in f:
csvRow = line.split()
writer.writerow(csvRow)
print(f"Successfully converted {txt_file_path} to {csv_file_path}.")通过以上的代码,我们实现了txt文件到csv文件格式的转换,如图所示:

打开转换成功的mr_labels.csv文件,并在第一行插入表头属性:

可以看到,我们完成了对文本标签的处理。
接下来,需要清洗mr.txt输入的文本,实现清洗文本的函数:
# 清理文本的函数
def clear_character(sentence):
pattern1 = '[^a-zA-Z0-9\u4e00-\u9fa5\s]' # 保留中英文字符、数字和空格
line = re.sub(pattern1, '', sentence) # 移除其他字符
return line.strip() # 去除首尾空白字符在读取数据的过程中,加载并调用清洗数据的函数:
# 加载和清理数据
with open('mr_dataset/mr.txt', 'r', encoding='utf-8', errors='replace') as file:
lines = file.readlines()
cleaned_lines = [clear_character(line) for line in lines]
data = pd.read_csv('mr_dataset/mr_labels.csv')
assert len(cleaned_lines) == len(data), "Number of reviews and labels must match"
之后对于原本的数据集,我们划分了数据集的训练集和测试集(加载的是Bert预训练模型,对参数没有很严格的要求,故没有划分验证集):
# 划分数据集
train_texts, val_texts, train_labels, val_labels = train_test_split(cleaned_lines, data['label'], test_size=0.2, random_state=42)特征提取的环节中,我们实现的算法采用了Bert词向量的特征提取方法。
Bert词向量特征提取:
class SentimentDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'label': torch.tensor(label, dtype=torch.long)
}该加载器包含了特征提取和参数设置。
由以上步骤,我们完成了对数据集的预处理。
四 模型训练与评估
首先加载Bert预训练模型,num_labels分类标签设置为2:
# 加载BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)由于bert的模型训练涉及到很多的参数,训练速度相对慢,所以我们在代码中将其放入了GPU中进行训练。
优化器采用的是AdamW,损失函数用的是交叉熵损失,两者的实现都借助于了pytorch框架。
# 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
criterion = torch.nn.CrossEntropyLoss()训练Bert模型的过程如下:
# 训练模型
model.train()
num_epochs = 5
for epoch in range(num_epochs):
total_loss = 0
model.train()
for batch in tqdm(train_loader, desc=f"Training Epoch {epoch + 1}/{num_epochs}"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
optimizer.zero_grad()
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
loss = criterion(outputs.logits, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_train_loss = total_loss / len(train_loader)
print(f'Epoch: {epoch + 1}, Loss: {avg_train_loss}')在过程中输出Loss函数损失以便于我们观察训练效果:
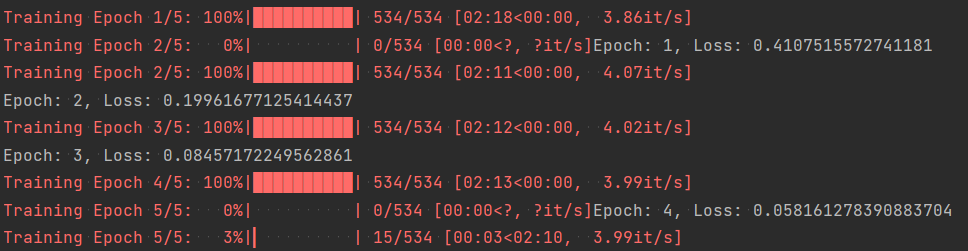
可以看出,模型经过多批次训练后,loss值下降明显。
训练完之后,进行评估验证:
model.eval()
all_labels = []
all_preds = []
all_probs = []
with torch.no_grad():
for batch in tqdm(val_loader, desc="Evaluating"):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
probs = torch.softmax(outputs.logits, dim=1)[:, 1] # 预测为正类的概率
_, predicted = torch.max(outputs.logits, 1)
all_labels.extend(labels.cpu().numpy())
all_preds.extend(predicted.cpu().numpy())
all_probs.extend(probs.cpu().numpy())
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
precision = precision_score(all_labels, all_preds)
recall = recall_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds)
auc_roc = roc_auc_score(all_labels, all_probs)
print(f'Test Accuracy: {accuracy * 100:.2f}%')各项评价指标的结果如下:
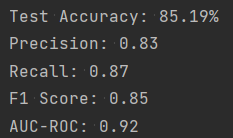
输出并可视化经过训练的bert模型的混淆矩阵:
# 生成并可视化混淆矩阵
conf_matrix = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=['Negative', 'Positive'], yticklabels=['Negative', 'Positive'])
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()输出混淆矩阵:
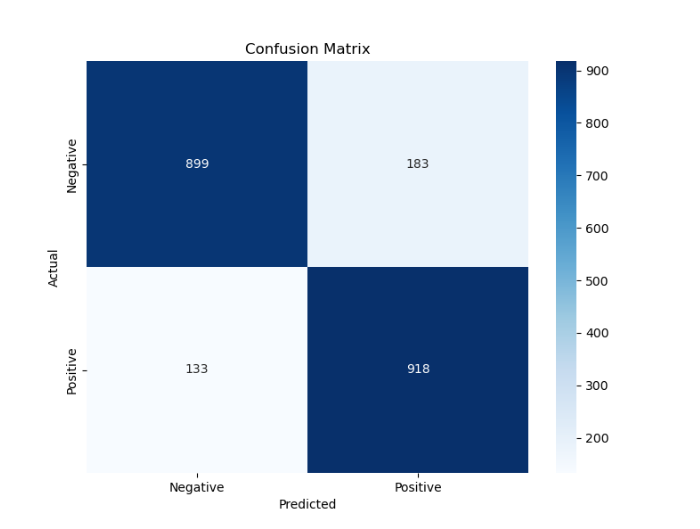
从各项指标来看,Bert在该文本分类任务中表现良好,体现出了较强的适应下游任务的能力,于是后续平台端部署的算法采用了Bert模型。
在该模型的基础上,我们利用该模型做了一个检测文本评论的页面。
如下图所示:
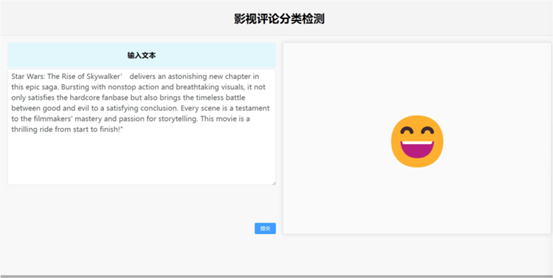
在实际场景中,该模型展示出了很好的检测评论的效果。



评论区